From Print to a Digital Edition Thanks to LLMs?
An experiment with the Gemini model based on the example of Acta Alexandri
In light of the development of large language models (LLMs), which are becoming increasingly capable in logic, contextual analysis, and reducing hallucinations, a number of legitimate questions arise: do current generations of models already enable reliable processing of sources in the form of scans and texts? Can AI, which is affecting many other fields of scholarship and business, also influence the world of digital scholarly editing?
As part of an experiment conducted in our Lab, we decided to test whether historians, working without technical support and using a publicly available LLM (known for strong performance in handwriting recognition—OCR—and image analysis), would be able to semi-automatically carry out the conversion of a printed source edition into a digital version in the TEI-XML standard, enriched with entity identification (Entity Linking), and also prepare a simple yet functional web application.
Case Study: Acta Alexandri Regis Poloniae (1501–1506)
The source material was the 1927 edition by Fryderyk Papée: Acta Alexandri Regis Poloniae, Magni Ducis Lithuaniae etc.. The aim was to move from scans of the publication to a prototype of an easy-to-use digital edition, while avoiding both manual work and programmer assistance, so as to simulate a situation in which a historian works independently with AI. The test material consisted of a sample of 11 pages (from physical page 19 to page 29) from a set of scans available in the Kuyavian-Pomeranian Digital Library; the scans are available as Public Domain material.
Methodology and Workflow
Publicly available tools were used to carry out the task: the Google AI Studio environment and the Gemini 3.1 Pro model. The process was designed so that it could be replicated by a person without advanced technical training:
- Dividing and converting the material: Due to output token limits, too many pages should not be processed at once. The DjVu format, in which scans are often made available in digital libraries, is not particularly well handled by language models; however, it is possible to create PDF files from the scans, for example containing around 10–12 pages each. A simple way to convert them is to use the SumatraPDF application, which reads DjVu files and allows the opened files to be “printed” to PDF format.
- Transcription and structuring: In Google AI Studio, prompts were used that required the model not only to read the text independently (even when present, the OCR layer in PDF files can be unreliable, especially in the case of italics), but also to analyse page layout, divide the material into sections, and save it in TEI-XML format.
- Enrichment (NER): The model automatically tagged persons (
persName), places (placeName), and dates (date). - Translation: The subsequent steps included automatic translation of the documents into Polish, which significantly facilitates access to the source content. The translation was also performed by the Gemini Pro model in AI Studio.
- Identification: linking previously tagged persons and places to reference databases, assisted by a language model. During the experiment, a script served as the tool for identifying persons and places (NEL) in the text, but shortly after the experiment a universal application was prepared that uses an LLM together with reference databases and does not require any IT expertise.
The attached PDF file is a fragment of an edition of letters and documents from the chancery of King Alexander Jagiellon. The edition was published in 1927; prepare a digital edition of these documents.
Task:
Transcription of the text from the PDF pages with output in TEI-XML format. Attention should be paid to the layout of the text.
Usually each page contains in the header the page number, the year to which the documents on the page refer, and the document numbers appearing on the page, for example: "9 1501 Nr. 10".
Each letter or document has clearly defined sections: it begins with a heading in bold with the document number, for example Nr 8.
Below the number there is a line in italics with the place and date of the document. In this section there may appear the abbreviation B. m. d. r., which means: without place, day, or year; this is often followed in parentheses by information about place and date, but these are details reconstructed by historians. In such cases, the data in parentheses may be marked with the <supplied> tag, for example <supplied reason="reconstruction">(<placeName>Gniezno</placeName>, 15 August 1502)</supplied>
Below this there is usually a brief summary, also written in italics, and beneath the summary, in italics and in a smaller font, information about the document itself, its source, etc.
The texts in italics are usually in Polish.
Below the information written in italics there is the main text of the document, usually in Latin.
Handling footnotes:
At the bottom of the page there may be footnotes to the text, and in the text there are references to them written as superscript numbers, more rarely as a superscript lowercase letter, e.g. a. Pay particular attention to the fact that footnote numbering resets on each page (for example, a document split across two pages may have two footnotes numbered 1).
Preserve the original footnote numbers (letters) in the n attribute (e.g. <note place="foot" n="a">).
Each footnote must be placed in the XML code exactly at the point in the main text where its reference mark (number / letter in superscript) appears.
Under no circumstances should footnotes with the same number be merged.
To avoid duplicates in the n attribute within a single document, add to the footnote number / letter the page number from the original file from which it comes, for example: <note place="foot" n="page_1-1"> for footnote no. 1 from page 1 and <note place="foot" n="page_2-1"> for footnote no. 1 from page 2.
Some footnotes are very long and continue onto subsequent pages; in such cases, below the wavy line separating the main text from the footnotes there appears a continuation of the footnote from the previous page without any number—append the content of such a continuation to the first part of the footnote.
In addition to marking the sections mentioned above, identify and tag the persons and places occurring in the text using the <persName> and <placeName> tags, as well as dates (the <date> tag)
Output:
An XML file compliant with the TEI-XML standard.
The attached file is an XML file (TEI-XML) containing a preliminary digital edition of the documents of King Alexander Jagiellon (early sixteenth century). Each document has its own <div> section, and within it the main text of the document appears in the section <div type="original" xml:lang="la">, where the language code is given in the attributes; usually it is Latin, but it may also be German. I would like to add translations of the main contents of the documents into Polish to the edition; after the described div section, a new one should appear, e.g. <div type="translation" xml:lang="pl"> with the translated content. In the translation, footnotes, notes, and the tagging of persons and places should be omitted—the aim is to include only the translated text of the document. The translation should be accurate, with a quality suitable for further historical research. Prepare an XML document extended with the translation.
The work was carried out on a sample of 11 pages, while the estimated time for similar work on a volume of approximately 600 pages is two to four days.
Identification of Persons and Places: the TEXT2NER Application
A major challenge in preparing digital editions is Entity Linking, that is, connecting a name appearing in the text with a specific identifier in a knowledge base. To address this, a prototype application called TEXT2NER was developed. It performs this process in two stages:
- Normalisation (entity recognition): The model analyses context and reduces names to the nominative case, identifying historical figures hidden behind Latin (or German) variants of names. For example: Sigismundus is normalised to Sigismund I the Old, and Andreas de Schamothuli to Andrzej Szamotulski.
- Verification in reference databases: The system searches Wikidata, WikiHum, and GeoNames. The LLM (in this case Gemini 3.1 Flash Lite) receives a list of suggestions from these databases and, on the basis of the context of the document and the data from the reference databases, selects the most probable candidate, assigning its identifier to the
refattribute in the XML tag.
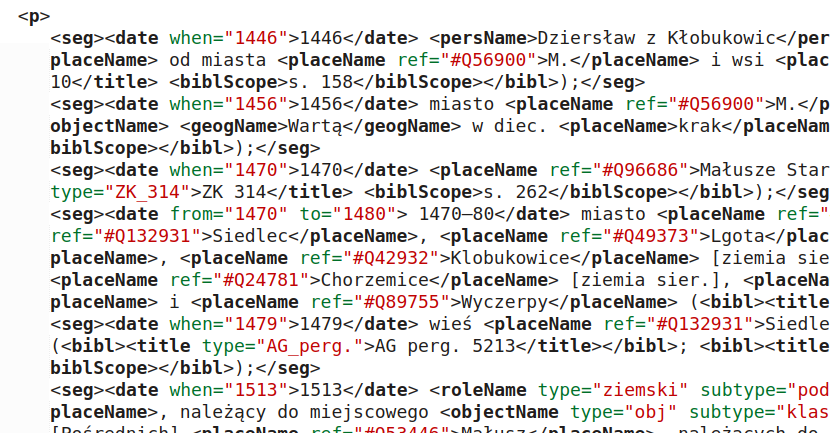
Results and Evaluation
- OCR quality: in order to evaluate the results, OCR was performed using the Tesseract system and then manually corrected; the resulting reading was compared with the text read by the model. The character error rate (CER) for the sample under study was only 1.5% (and after ignoring spaces it fell to 0.53%).
- Structure: The model recognised headings, summaries, the main text, and footnotes almost flawlessly (including those continued across subsequent pages).
- Name normalisation: Among 90 occurrences of persons, 87 were normalised correctly. For example, the figure described in the document as "Johannes von Gots gnaden Bischoff zcu Meyssenn" was correctly recognised as Johann von Saalhausen.
- Identification of persons: 75 identifiers for persons were established correctly, 10 incorrectly, in 4 cases the application did not find an identifier, and in one case the identification is doubtful. Retrieval failed, for example, when a given person was described only in German-language sources (German knowledge bases such as Ulricus von Wolfferstorff in saebi.isgv.de, or only in German-language entries in Wikidata), while the application searched for a Polonised form of the name.
- Place normalisation: Of 93 occurrences of places (towns, countries), all were normalised correctly. It should be noted, however, that in most cases these were larger and better-known places, though sometimes in less familiar historical forms, such as Gnysen or Thorun.
- Identification of places: 80 identifiers for places were established correctly, 7 probably incorrectly, and 6 incorrectly. The problems concerned, for example, regions that were identified with modern entities, while Wikidata contained their counterparts from the period in which the documents were created (e.g. Lithuania → Grand Duchy of Lithuania).
- Translations: Automatic translations convey the general meaning of the documents, but they are not yet sufficient from the perspective of historical research.
When assessing these results, one must of course remember the small scale of the experiment (only 10 documents).
Vibe Coding, or an Application “on Demand”
The culmination of the work was the creation of a web application to present the results. Using the method of so-called vibe coding (an interactive session with the Gemini Pro 3 model, without writing code independently), a functional browser based on Python and Flask was created in about an hour. Another hour and 12 prompt iterations made it possible to introduce the necessary corrections and additions to the application.
The application offers:
- Browsing the list of documents (with pagination).
- A two-column layout for the displayed document (original text vs. Polish translation).
- Highlighted entities with links to reference databases.
- Full-text search and faceted filtering by persons and places.
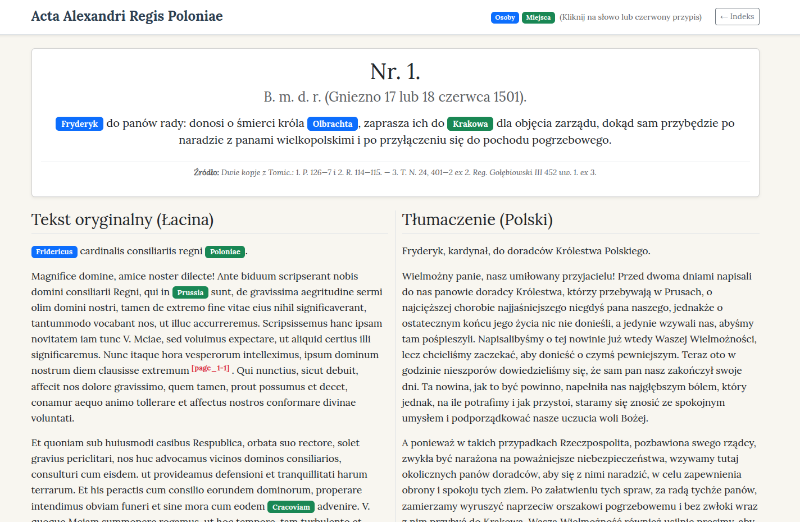
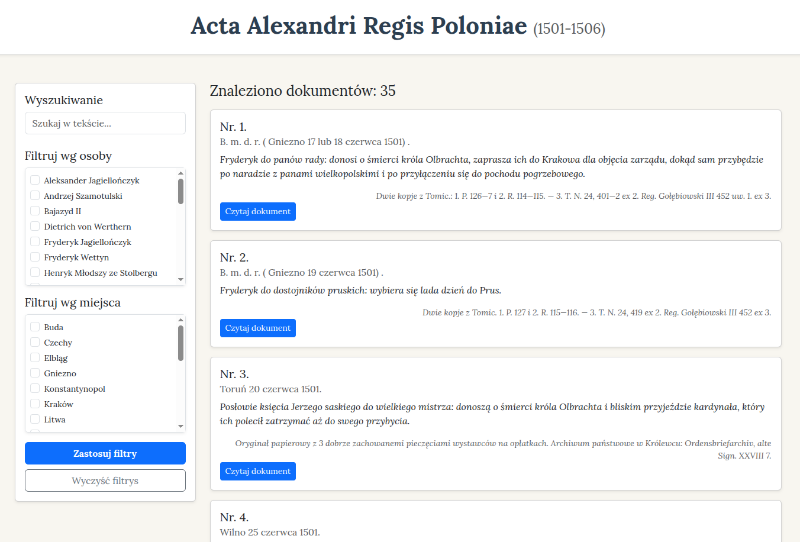
Attached is a digital edition of the documents of Alexander Jagiellon in the form of a TEI-XML file. For historians, however, such a raw form will be difficult to read. Ideally, it should be made available as a simple web application. The application should allow users to browse a list of documents with basic metadata and excerpts from summaries. After selecting a document, the system should display the header data, the text with colour highlighting of persons and places, and alongside it also a Polish translation. It would also be useful to have full-text search and filtering by persons and places. Footnote numbers in the documents should be clickable and display a popup with the footnote text. In addition to being colour-highlighted, persons and places should also display additional information in tooltips on mouseover (e.g. identifiers where these have been established).
Prepare such a simple application using Python, the Flask framework, and Bootstrap.
Conclusions:
The results of the experiment suggest that LLMs (or AI tools more broadly) may substantially lower the threshold of entry in the field of creating digital editions, taking over tasks previously reserved for programmers or advanced digital humanists; these models may also replace specialised tools used in this field. It must also be acknowledged that the use of LLMs significantly reduces working time (the time required to create the edition; verification of correctness remained manual, so the time-intensiveness of that stage did not change).
But does this mean that specialists will become unnecessary? In the process of conversion and initial processing, it may seem so, although IT support remains advisable for verifying files prepared by LLMs. The same applies to application development—LLMs are effective for rapid prototyping, but one must remember that testing, deployment to a server, and similar stages remain necessary. It is also clearly the role of the human researcher to provide critical verification of the results. Historians must ultimately approve (and, where necessary, correct) the quality of transcription, the certainty of the identification of proper names, and the nuances of translating medieval Latin.
It should be emphasised that this was a very simple test, based mainly on the capabilities of a single model—Gemini—and that only a small sample of documents was processed. For much more advanced work on this topic, we refer readers to the Further Reading section below.
A critical element in the use of LLMs is the reliability of their outputs. From version to version, one can observe that models are handling the problem of hallucinations increasingly well; nevertheless, one should not expect hallucinations to disappear entirely. What level of error in AI-generated results is acceptable—that is, what level remains correctable by a human in less time than would be required to perform the work entirely by hand or with traditional tools? The question of whether we have already reached that stage remains open, although the widespread use of AI in other areas, such as programming, may suggest that we have.
We invite you to explore the Acta application (the “digital edition” of Acta Alexandri Regis Poloniae):
https://ai.ihpan.edu.pl/acta/
The source code of the application is available in the repository: https://github.com/pjaskulski/digital-edition-for-fun.
Further Reading:
- Strutz, Sabrina. A Multi-Dimensional Evaluation Framework for Assessing LLM Performance in TEI Encoding. Journal of Open Humanities Data 12 (March 2026): 39. https://doi.org/10.5334/johd.484.
- Boscariol, Marta, Luana Bulla, Lia Draetta, Beatrice Fiumanò, Emanuele Lenzi, and Leonardo Piano. Evaluation of LLMs on Long-Tail Entity Linking in Historical Documents, arXiv:2505.03473 (2025).
- Haffoudhi, Samy, Fabian M. Suchanek, and Nils Holzenberger. LELA: An LLM-Based Entity Linking Approach with Zero-Shot Domain Adaptation, arXiv:2601.05192.
- Daniel Vollmers, Hamada Zahera, Diego Moussallem, and Axel-Cyrille Ngonga Ngomo. Contextual Augmentation for Entity Linking Using Large Language Models, Proceedings of the 31st International Conference on Computational Linguistics, n.d., 8535–45. https://aclanthology.org/2025.coling-main.570/
- Rosu, Paul. LITERA: An LLM Based Approach to Latin-to-English Translation. arXiv:2504.10660. Preprint, arXiv, April 14, 2025. https://doi.org/10.48550/arXiv.2504.10660.